It has been a long time since Span and Memory joined into our world, but I recently had a chance to look at them. If you want to use them you should have at least .Net Core 2.1. If you want to get detailed information you can look at https://docs.microsoft.com/en-us/archive/msdn-magazine/2018/january/csharp-all-about-span-exploring-a-new-net-mainstay So what are we going to do here is we will implement a solution to parsing text files. The first one will be implemented by classic .Net codes and the second one will be implemented by Span and Memory.
We will write a method and the method will read all of the text inside the file then it will count the occurrences of the words. Like a word how many times used in the text.
For example, we have a text file like this;
| Murat Pikacu |
| Charmander Murat Pikacu |
And the result should be;
| Word | Count |
|---|---|
| Murat | 2 |
| Pikacu | 2 |
| Charmander | 1 |
So let’s start to write our project;
In order to implement multiple parsers, we need one interface to return pairs.
public interface IFileParser
{
Task<Dictionary<string, int>> Parse(string filePath, CancellationToken cancellationToken = default);
}
Our classic Parser;
Because StreamReader has the ReadLine method we will use it. Then we count if there is an occurrence.
public class TextFileParser : IFileParser
{
public async Task<Dictionary<string, int>> Parse(string filePath, CancellationToken cancellationToken = default)
{
var dic = new Dictionary<string, int>();
string line;
using (var file = new StreamReader(filePath))
{
while ((line = await file.ReadLineAsync()) != null)
{
if (cancellationToken.IsCancellationRequested)
{
break;
}
var words = line.Split(" ").Where(x => !string.IsNullOrWhiteSpace(x));
foreach (var word in words)
{
if (dic.ContainsKey(word))
{
dic[word] = dic[word] + 1;
}
else { dic[word] = 1; }
}
}
}
return dic;
}
}
And the second one is here. Here I tried to write code to do the same thing with our classic example. Because there is no ReadLine method that implements Memory buffer I wrote something as if it is ReadLine.
public class TextFileMemoryParser : IFileParser
{
public async Task<Dictionary<string, int>> Parse(string filePath, CancellationToken cancellationToken = default)
{
var dic = new Dictionary<string, int>();
bool goon = true;
string line;
var chars = new List<char>();
using (var file = new StreamReader(filePath))
{
Memory<char> memory = new Memory<char>(new char[1]);
while (goon)
{
await file.ReadAsync(memory, cancellationToken);
goon = !file.EndOfStream;
if (file.EndOfStream) { chars.Add(memory.Span.ToString()[0]); }
if (file.EndOfStream || memory.Span.Contains('\n') || memory.Span.Contains('\r'))
{
line = string.Create(chars.Count, chars, (x, y) =>
{
for (int i = 0; i < x.Length; i++)
{
x[i] = y[i];
}
});
foreach (var word in line.Split(" ").Where(x => !string.IsNullOrWhiteSpace(x)))
{
if (dic.ContainsKey(word))
{
dic[word] = dic[word] + 1;
}
else { dic[word] = 1; }
}
chars.Clear();
}
else
{
chars.Add(memory.Span.ToString()[0]);
}
}
}
return dic;
}
}
As you can see above we have Memory
So let’s see what their effects are on files.
public async Task OnPostUploadAsync()
{
if (Upload == null) return;
_cts = new CancellationTokenSource();
var file = Path.Combine(_environment.WebRootPath, "uploads", Upload.FileName);
using (var fileStream = new FileStream(file, FileMode.Create))
{
await Upload.CopyToAsync(fileStream, _cts.Token);
}
foreach (var _fileParser in _fileParsers)
{
Stopwatch sw = Stopwatch.StartNew();
WordsWithCount = await _fileParser.Parse(file, _cts.Token);
sw.Stop();
if (_fileParser is TextFileParser)
{
DefaultParser = sw.Elapsed.TotalSeconds.ToString();
}
else if (_fileParser is TextFileMemoryParser)
{
MemoryParser = sw.Elapsed.TotalSeconds.ToString();
}
}
}
After injecting the list of IFileParser we watched them on a higher than 50MB text file and the result is an average of 7 seconds with MemoryParser.
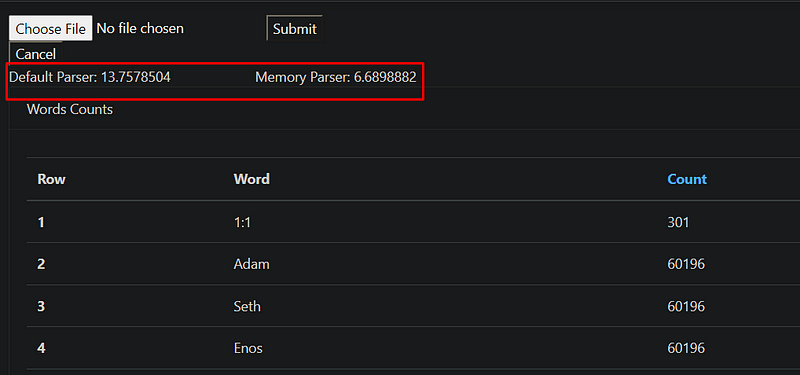
Also, if you look at diagnostic tools you can see that CPU usage is less than the classic one. If you try on a file larger than 450MB you can see below that it takes %50 shorter than the classic one. And these results are not got on the released version they get on the debug version.

Note: If there is any problem with my codes don’t hesitate to comment about it.